Acustica psicofisica
L’essere umano dispone di un sistema uditivo che gli permette di sentire gli stimoli sonori. Tale sistema se confrontato con tutti gli altri sistemi di percezione sonora inventati dall’uomo si rivela sempre di gran lunga il migliore, pur restando molto soggettivo, variando da individuo ad individuo, e presentando delle limitazioni nelle ampiezze e nelle frequenze percepibili. Esso inoltre è dotato, a differenza degli altri sistemi, di una risposta proporzionale non allo stimolo ma al suo logaritmo.
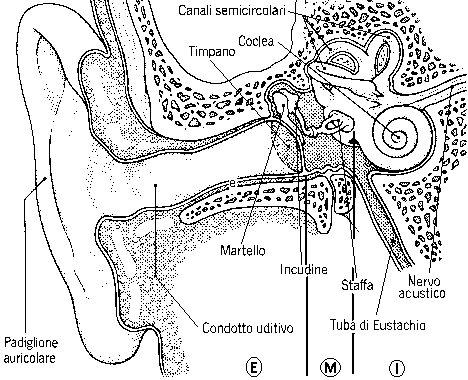
I sistema uditivo umano rappresentato in figura 1 è costituito da tre blocchi principali: l’orecchio esterno, l’orecchio medio e l’orecchio interno.
Figura 1. Sezione dell’orecchio.
E: orecchio esterno; M: orecchio medio; I: orecchio interno.
L’orecchio esterno è costituito dal padiglione auricolare, dal condotto uditivo e dal timpano. Il padiglione auricolare è la parte più esterna del sistema: il suo compito è quello di raccogliere i suoni provenienti dall’ambiente e, tramite la sua forma particolare, di convogliarli all’interno del condotto uditivo. Questo a sua volta, dopo aver amplificato il segnale di anche 12 dB tramite risonanza grazie alla propria forma a tromba, indirizza lo stimolo sonoro verso il timpano.
Il timpano, al termine del condotto uditivo, è una membrana impermeabile sia all’acqua che all’aria che separa l’ambiente dell’orecchio esterno da quello dell’orecchio medio e che viene posta in vibrazione dall’onda sonora di pressione che il resto del sistema ha convogliato, amplificato e messo in risonanza verso esso. Così, sotto lo stimolo il timpano vibra e a sua volta trasmette la vibrazione ad una serie di ossicini posti nell’orecchio medio con cui è in contatto. Poiché il timpano deve separare due zone entrambe piene d’aria, l’orecchio esterno e quello medio, per minimizzare l’energia del segnale dispersa nella trasmissione, esso ha un’impedenza acustica molto simile a quella dell’aria.
L’orecchio medio è costituito da un cavità piena d’aria, in comunicazione diretta con l’esterno tramite un condotto detto tuba di Eustachio, in cui sono posti tre ossicini chiamati martello, incudine e staffa. In contatto con il timpano e con la parte più interna dell’orecchio il loro compito è quello di trasportare il segnale dal timpano all’orecchio interno. Poiché però le cavità dell’orecchio medio ed esterno sono riempite d’aria mentre quelle dell’orecchio interno sono riempite di un fluido detto endolinfa con densità molto maggiore, per evitare una dispersione dell’energia del segnale è necessario adattarlo perché esso possa essere percepibile dall’orecchio interno. Per questo gli ossicini fungono da leve in serie che trasformano i grandi spostamenti con piccole forze del timpano in piccoli spostamenti con grandi forze sull’orecchio interno. In tal modo essi hanno la funzione di amplificatori passivi, amplificando il segnale fino a 10 dB ma riducendone lo spostamento. Sono perciò degli adattatori di impedenza.
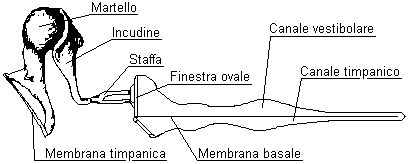
Figura 2. Ossicini e sezione della coclea
L’orecchio interno è costituito dalla coclea, dai canali semicircolari e dal nervo acustico. I canali semicircolari in realtà non servono all’udito ma sono la sede del senso dell’equilibrio. La coclea ( fig.2 e fig. 3) invece è costituita da due condotti paralleli, il canale vestibolare e il canale timpanico, separati da una parete chiamata membrana basale. I due condotti sono riempiti di endolinfa e sono in comunicazione tra loro tramite un’apertura alla fine della membrana basale. La coclea riceve il segnale dalla staffa tramite la finestra ovale, una membrana che separa l’orecchio medio da quello interno, e che lo trasmette all’endolinfa nel canale vestibolare. Le variazioni di pressione del fluido nei due canali vengono quindi percepite dalle cellule cigliate presenti sulla membrana basale che trasmettono l’informazione al nervo acustico. La membrana basale funge da filtro molto selettivo per quanto riguarda le frequenze percepibili: essendo più tesa e fine vicino alla finestra ovale da cui entra il segnale e via via più spessa e lasca allontanandosene ha una risposta differente al variare delle frequenze. Per la sua conformazione essa permette di percepire prima le componenti del suono ad alta frequenza e solo più tardi quelle a bassa frequenza. Tutte le informazioni estratte dal segnale dalle cellule cigliate vengono allora elaborate da una rete neurale che ritrasmette al cervello come il suono è distribuito alle varie frequenze. A causa però della limitatezza del canale di trasmissione se sono presenti troppe informazioni i suoni meno intensi con frequenze nelle vicinanze di altri suoni con intensità molto maggiori vengono trascurati e non percepiti: si ha perciò il fenomeno detto del mascheramento.
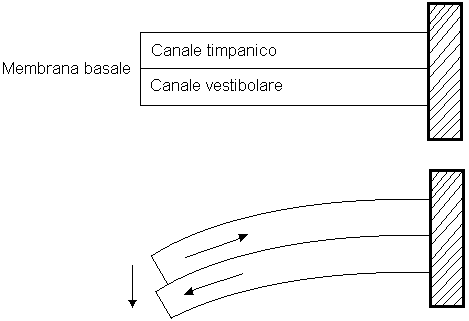
Figura 3. Sezione della coclea e percorso del segnale
Analizzando la risposta dell’orecchio alle diverse frequenze e pressioni, pur essendo questa molto soggettiva, è possibile in linea generale ricavare un grafico detto diagramma di sensazione che mostra quali suoni alle varie frequenze e intensità possono essere percepiti dal sistema uditivo umano. Tale gamma di suoni può essere racchiusa tra due limiti detti soglia dell’udibilità e soglia del dolore: la soglia dell’udibilità rappresenta il limite inferiore di intensità che può essere percepito, la soglia del dolore rappresenta il limite superiore di intensità che non provoca dolore.
Fletcher e Munson, due studiosi che analizzarono la risposta dell’orecchio umano, riuscirono a descrivere questo grafico con l’uso delle curve isofoniche. Essi utilizzando un suono di riferimento a 1000 Hz effettuarono dei test soggettivi variando l’intensità del suono alle varie frequenze per verificare quale produceva un’uguale sensazione sonora. In tal modo ricavarono delle curve isofoniche, rappresentate nel diagramma di Fletcher e Munson (fig. 4), che rappresentavano come variava la sensazione sonora all’interno del campo dell’udibile. La più alta di tali curve corrisponde alla soglia del dolore, la più bassa alla soglia dell’udibilità.
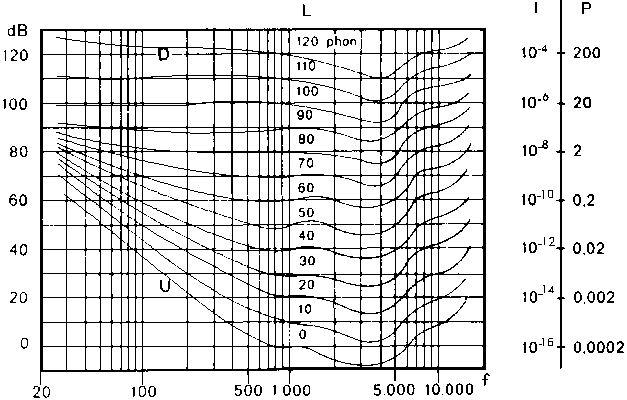
Figura 4. Audiogramma di Fletcher e Munson.
f: frequenza in hertz; L: livello di sensazione sonora; D: soglia del dolore; U: soglia dell’udibilità; I: intensità in watt/cm¹ dell’onda sonora piana; P: pressione in dine/cm¹.
Osservando tali curve è possibile notare che per un’uguale
sensazione più bassa (o alta) è la frequenza maggiore (o minore)
deve essere l’intensità dello stimolo: si è perciò
scoperto che l’udito umano non ha risposta lineare. La
sensazione a una frequenza campione di 1000 Hz si raddoppia se l’intensità
cresce di un fattore di circa ![]() per volta. Si è pensato
perciò di utilizzare una scala logaritmica invece che lineare
per rappresentare tali grafici. Un esempio può essere:
per volta. Si è pensato
perciò di utilizzare una scala logaritmica invece che lineare
per rappresentare tali grafici. Un esempio può essere:
Pressione in Pa |
Livello di Sensazione |
0,01 |
1 |
0,0316 |
2 |
0,1 |
3 |
0,316 |
4 |
1 |
5 |
Per misurare la sensazione sonora si utilizza la scala di Bell (1847-1922 scienziato che inventò la centralina di commutazione, studiò a fondo il fenomeno della sensazione sonora e fondò la AT&T). Nella sua scala il valore del livello della sensazione è dato dalla formula:
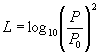 (1)
(1)
dove P è la pressione sonora, e ![]() è la
pressione sonora soglia a 1000 Hz, cioè la pressione del più
piccolo suono udibile a 1000 Hz. L’unità di misura del
livello sonoro è il bell (B).
è la
pressione sonora soglia a 1000 Hz, cioè la pressione del più
piccolo suono udibile a 1000 Hz. L’unità di misura del
livello sonoro è il bell (B).
I valori ottenuti con la formula empirica (1) corrispondono bene a quelli trovati sperimentalmente. Poiché però l’unità è troppo grande si preferiscono usare i suoi sottomultipli come 1 B = 10 dB (decibell) e quindi la seguente formula misurata in dB:
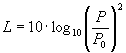 (2)
(2)
E’ da notare che i valori dei livelli sonori ottenuti con le formule (1) e (2) sono tutti positivi; infatti lo 0 corrisponde al livello minimo udibile.
Come valore di pressione per il calcolo in queste formule non si usano i valori massimi ma i valori medi efficaci (RMS) anche per la facilità di misura degli stessi. Il tempo minimo per la misura di tali valori di pressione deve perciò essere di 125ms.
Poiché la risposta dell’orecchio umano allo stimolo sonoro è logaritmica in ampiezza e varia al variare della frequenza si è deciso di uniformare gli standard di misura approssimando la risposta dell’orecchio umano con un filtro di compensazione che tenga conto delle differenze tra le varie frequenze. A questo proposito sono stati creati i seguenti filtri:
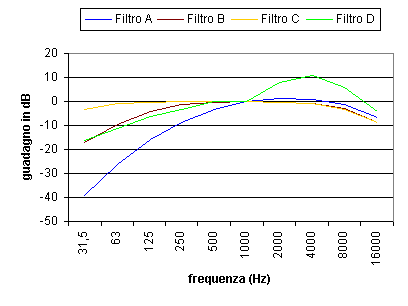
Figura 5. Filtri di ponderazione
Nella pratica i filtri maggiormente utilizzati sono quello A e quello C e le loro risposte sono misurate rispettivamente in dB(A) e in dB(C). Mentre il filtro A è utilizzato a valle del microfono per misurare i valori efficaci medi e stimare la risposta effettiva dell’orecchio, il filtro C è principalmente utilizzato per misurare i massimi di picco di suoni impulsivi, forti e molto brevi, tipo quelli di esplosioni.
Il limite stabilito per legge per l’uomo da un normativa CEE di valore massimo di picco è LP,MAX,PEAK = 130 dB(C), ovvero 130 dB misurati con il filtro C. In Italia invece la vecchia normativa prevede LP,MAX,PEAK = 140 dB(LIN), ovvero 140 dB misurati su scala lineare: tale valore è più tollerante nei confronti delle alte frequenze ed ha l’inconveniente di segnare massimi a causa della non ponderazione dell’intensità di eventi anche non acustici a bassa frequenza.
Effetti del rumore sull’uomo
Se il sistema uditivo umano rimane esposto a rumori molto intensi può essere soggetto ad una perdita della capacità uditiva, così come a danni legati all’equilibrio (nausea, vomito, labirintite, perdita dell’equilibrio, ecc). Ciò può accadere se il soggetto subisce livelli sonori molto alti anche per brevi periodi: in tal caso subito e fino ad una mezzora dopo si possono avvertire dei fenomeni di tal tipo seppur temporanei. Nel caso invece di esposizione a livelli medio alti per tempi prolungati possono insorgere problemi permanenti all’udito. Per verificare tali eventualità si monitorizza la capacità uditiva del soggetto sottoponendolo a un test acustico con suoni di livello via via crescente per stabilire il minimo livello sonoro udibile.
Un individuo senza danni uditivi dovrebbe presentare un tracciato della perdita in dB delle frequenze percepite per le due orecchie di questo tipo:
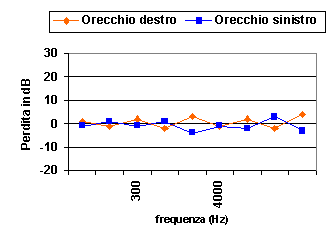
Figura.6. Perdita media per orecchio
Nel caso invece di un individuo con danni uditivi medi si riscontrano spesso tracciati di questo tipo:
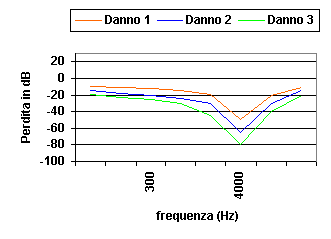
Figura 7. Perdite per danni
In questi casi si può notare che l’individuo tende a non percepire più distintamente le alte frequenze nell’intorno dei 4000 Hz, questo perché l’orecchio umano è molto sensibile in quell’intervallo. A causa del fatto che la maggior parte delle consonati del parlato viene espressa con suoni contenenti quelle frequenze diventa sempre più difficile capire il parlato, pur cogliendo con nitidezza le vocali. Questo è un problema molto diffuso tanto che in Italia due milioni e mezzo di persone ne soffrono, circa il 5% della popolazione nazionale. A scopo di curare tale problema si utilizzano delle protesi acustiche con lo scopo di enfatizzare le parti in frequenze danneggiate: le protesi devono presentare un indice di guadagno variabile con la frequenza, che si adatti alle variazioni dello stimolo e che ricostruisca l’esatto guadagno nelle varie frequenze di un orecchio sano.
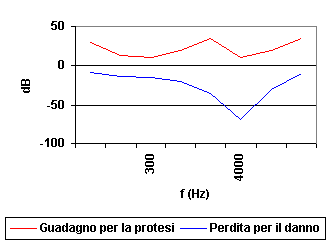
Figura 8. Guadagno della protesi
Somma di livelli sonori
La somma di due o più livelli sonori può essere coerente o incoerente.
La somma si dice coerente se entrambi gli stimoli sono identici e in fase. Questo è il caso riportato in figura 9.
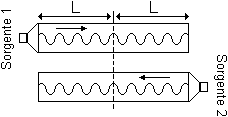
Figura 9. Sorgenti coerenti
In questa situazione, se i due livelli sonori sono L1=L2 ed i segnali hanno entrambi la stessa pressione istantanea P1=P2 poiché sono lo stesso identico segnale inviato contemporaneamente da due sorgenti equidistanti dal bersaglio, la pressione totale risulta la somma delle pressioni e il livello totale è facilmente ricavabile:
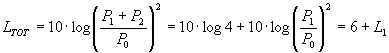 (3)
(3)
Nel caso L1 = 70 dB allora
LTOT = L1 + L2 = 70 dB + 70 dB = 6 dB + 70 dB = 76 dB.
Questa situazione è estremamente anomala perché è praticamente impossibile trovare due sorgenti di segnale coerenti.
La somma si dice incoerente se i due stimoli differiscono per fase e/o intensità. Questo è il caso riportato in figura 10.
Figura 10. Sorgenti incoerenti
Questo può essere il caso di due casse acustiche collegate ad uno stereo: i due segnali sono diversi perché hanno fase casuale a causa delle riflessioni nell’ambiente. Ci possono allora essere momenti in cui due picchi di pressione si sommano enfatizzandosi e altri in cui un picco ed una valle si sommano eliminandosi. In tal caso per il principio di conservazione dell’energia l’intensità sonora è data dalla somma delle due intensità dei segnali reali, la densità di energia sonora à data dalla somma delle due densità mentre per la pressione non vale tale uguaglianza. La pressione al quadrato risulta proporzionale alla densità di energia e vale la formula:
![]() (4)
(4)
e quindi il livello sonoro totale diventa:
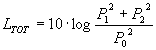 (5)
(5)
Come nel caso precedente
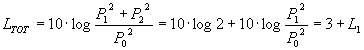 (6)
(6)
e perciò se L1 = L 2= 70 dB allora
LTOT = L1 + L2 = 70 dB + 70 dB = 3 dB + 70 dB = 73 dB
Dalla formula (5), al variare della differenza tra i due livelli sonori si può ricavare il seguente grafico che stabilisce quale valore va aggiunto al livello sonoro maggiore per la somma di due livelli sonori:
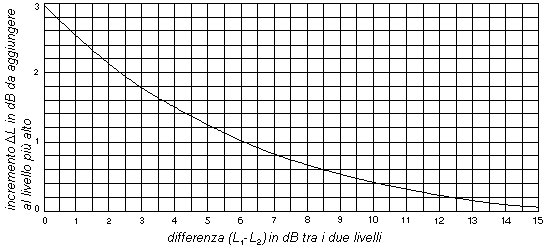
Figura 11. Grafico incrementi per somma incoerente
Questa curva stabilisce che se i due livelli sonori da somma differiscono di più di 15 dB il livello sonoro superiore sovrasta l’altro e ne rende trascurabile il contributo. Il suono con livello inferiore rimane udibile ma un fonometro non sarebbe in grado di stabilire se il suo contributo sia presente nel suono totale.
Se per esempio i due livelli sonori fossero di 70 dB e di 65 dB la loro somma incoerente sarebbe:
![]()
Se invece si hanno più di due livelli sonori di cui viene fornito lo spettro si può calcolarne il livello totale. Infatti dalla formula (2) si può ricavare:
![]() (7)
(7)
che sostituito nella (5) da:
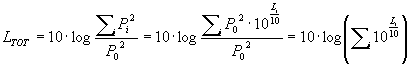 (8)
(8)
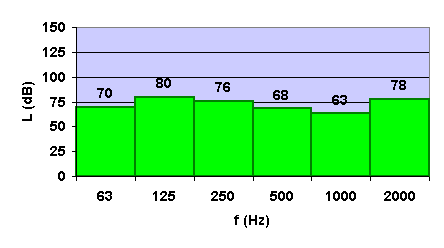
Figura 12. Spettro in bande d’ottava dei livelli sonori di un segnale
Con i dati dello spettro in figura 12 si ricava:
![]()
Questo però è il valore calcolato con la scala lineare. Nel caso si desideri il valore preciso nella scala A bisogna modificare banda d’ottava per banda d’ottava i valori dei livelli con quelli del filtro A.
Frequenza di centrobanda f (Hz) |
Livello sonoro lineare L (dB) |
Correzione di tipo A AW (dB) |
Livello sonoro ponderato LW (dB(A)) |
63 |
70 |
-26,2 |
43,8 |
125 |
80 |
-16,1 |
63,9 |
250 |
76 |
-8,6 |
67,4 |
500 |
68 |
-3,2 |
64,8 |
1000 |
63 |
0 |
63 |
2000 |
78 |
+1,2 |
79,2 |
In questo modo, applicando la ponderazione alle bande d’ottava, si ottengono i livelli sonori ponderati in dB(A). Il livello sonoro totale equivalente ponderato con il filtro A è allora:
![]()